Database Design Problem You have been hired to review the accuracy of the books of Northeast Seasonal Jobs International (NSJI), a job broker. NSJI matches employers whose business is seasonal (like ski resorts) with people looking for part time positions at such places. Employers are located in the Northeast (New England), but recently expanded to include parts of Canada. NSJI maintains all of this information in a flat file spreadsheet.
1-Reviewer’s Perspective
Currently, the company NSJI is maintaining the database in a flat file spreadsheet. It is maintaining its data in the form of Excel tables. It can cause many problems for the management of the data. As the data is in the flat file form of a spreadsheet, the possibility of data duplication is possible.
Another problem is that data can get scattered in different files. It is another problem when the data is to be extracted as well. The extraction of the data scattered in different files is also very difficult. In the format of the flat file, the data is not formatted in normalization. There is no normalization in the flat file format of NSJI database. When the data is not normalized, the probability of making a mistake is greater as well. Furthermore, the auditor job of the checking the process of the data imputation becomes quite difficult when the data is not in the normalized form. This un-normalized form of the database makes the operation of auditors time-consuming and tiresome.
From the perspective of the reviewer, NSJI approach of data management becomes quite erroneous. As the structure is not normalized, the possibility of including the updated anomalies is not essentially easily avoided. It becomes a huge functional dependency for the database. The data because of this becomes inconsistent, and an update in the database makes it difficult for the manager to add any data without making changes to the existing one. The basic operation of adding or subtracting becomes a difficult job.
From an auditor’s perspective, this problem becomes more complicated. The reliability of such documents is considered low. When an auditor is trying to assess the reliability and materiality of the records, the difficulty to perform simple functions creates suspicions for auditors on the accuracy of the data. There is a high chance of error in the non-normalized data sheets. Multiple entries can be made without the knowledge of the reviewer. Duplicates can be found under same Identification numbers. It also implies that all the information about the repeated ID will also repeat causing massing up of the whole database.
NSJI has stored data in a flat file format. In this type of format, every division of the spreadsheet preserves its record established in its system. It is being said; there can be some inconsistent entries in the data because of repetition and typo errors. As this data is not in normalized form, the repetition is possible. It is also depicted in the NSJI data sheet. The Employer ID 10151 is repeated for four times in the Employer ID Field. It does not mean that there are only four errors. The entire rows of these primary keys are repeating as well. It means that the Employer Name, Position, Zip Code, Country, Contact the First name, Contact the last name, Phone, state, and comments, all attributes are repeating as well. Thus, the probability of error in this format is very high. Furthermore, any updates if needed in the data would possibly require making changes in more than one row of the data. Thus, anomalies may occur while adding or changing of the data stored.
2-Reduce the Possible Impact of potential Problems
Normalization:
Normalization is a process in which the structures of the tables are formed in a way that it must comply with several rules which are known as the normal forms. These normal forms are used to transform data which are un-normalized form into normal form. It causes a reduction in the possibility of errors like anomalies while adding, deleting or changing the stored data. The main aim of the process of normalization is to generate a database model which is based on the relations in 3rd normal form. The normalization process includes three steps towards a normalized form of a data table.
First Normal Form | 1NF:
The 1NF require the data to erase any repeating groups. The first normal form, however, includes functional dependencies. These functional dependencies are known as update anomalies. As a result of these functional dependencies, the data can be inconsistent. It can also require changes in multiple rows while updating the data. Furthermore, the addition and deletion of data are problematic in this form. Moreover, fractional dependencies, an, i.e., an attribute that are dependent on the part and not a whole portion of the primary keys are present in this form.
Second Normal Form | 2NF:
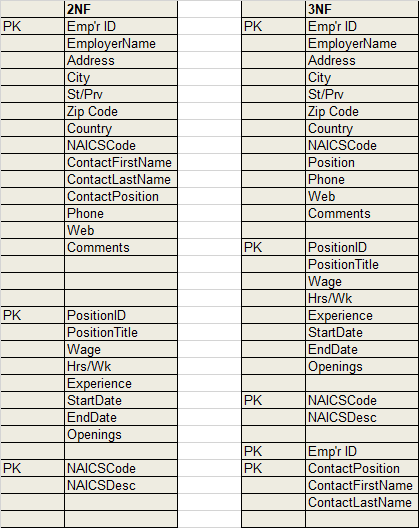
For reducing these problems, the data is then transformed into the second normal form or 2NF. It is a form of a data table in which a data table is required to be in 1NF and have no partial dependencies. Thus, any non-key attribute that is dependent only on the part of the principal key are erased. New tables are formed for each of the subsets of the table which is partially dependent on the primary or composite primary key. A primary key is given to new table created. It makes all the tables dependent completely on their primary keys.
3rd Normal Form | 3NF:
Still, there is a possibility of the presence of transitive type of dependencies. Thus, the table is converted into 3rd normal form or 3NF to erase such dependencies. This type of dependency only exists when a non-key attribute of a data table is dependent functionally on any other non-key attribute. These are also erased by creating another table and giving it a new primary key, the non-key attribute on which it was dependent. Now all the tables are in the 3rd normal form, 3NF which means that
- There are no repeating groups
- There are no functional dependencies; the addition, editing, deleting or changing of data does not require changes in multiple rows of data
- There no attributes of non-key which are dependent partially on the composite primary key for example there are no partial dependencies
- There are no attributes of non-key so they are independent for example there is no transitive type of dependency
- Every table has its principal key while other non-key attributes are not independent and depend entirely on the principal key
- Unique attributes are present in each table
- There is no repetition in the data tables
These all problems are erased by transforming of the data tables in a normalized form. By following this, the database can be easily managed, edited, reviewed, and audited. It is also shown in the database of the NJSI which has been normalized to 1NF, 2NF and then to the 3NF, i.e. 3rd normal form.
3-To Create a Conceptual Entity Relationship Diagram (ERD)
ERD Diagram for NJSI

4-Database Normalization
Note: PK=Primary Key